
苏州纳米所刘欣研究员、周扬帆博士等在非凸优化算法研究方面取得进展
近年来,深度学习在材料科学领域中的原子模拟、材料成像、光谱分析等方向取得快速发展。与此同时,在芯片设计领域,为了满足边缘计算场景的算力需求,人工智能芯片也正在逐步完成与深度神经网络的高度适配。目前,由OpenAI公司推出的ChatGPT模型正在引领一次新的技术变革,该模型的本质就是一个超大规模的深度神经网络,属于深度学习框架。根据实践目标可以将深度学习划分为两个阶段:训练阶段和推理阶段。训练阶段是指通过一定的训练算法得到深度模型的参数;推理阶段就是将深度模型应用到实际场景中进行预测和分析,比如目前的ChatGPT模型就已经处于推理阶段。
由于深度模型具有庞大的特征参数和高维的数据,比如ChatGPT模型包含1750亿个参数、BERT模型含有1亿个以上的参数,因此深度模型训练越来越成为一项极具挑战性的任务。通常来说,为了训练深度模型,可以通过最小化损失函数的值,将其转化为一个典型的非凸优化问题。然而,非凸优化问题中优化算法的收敛性往往是一个难以解决的问题。另外,因高维征向量带来的高昂计算成本问题也是制约深度模型训练任务顺利进行的另一个难题。
中国科学院苏州纳米技术与纳米仿生研究所刘欣研究员、周扬帆等针对非凸优化问题中自适应优化算法的高维向量运算问题,提出了一种基于块坐标下降的自适应优化算法,简称为RAda(伪代码如图1所示)。该算法利用块坐标下降优化技术,在每轮迭代时随机的选取特征向量的一块坐标完成梯度计算及其他向量运算,从而大大减少每轮迭代的计算成本,减轻了深度模型训练对硬件设备的严重依赖。
 图1.RAda算法伪代码
图1.RAda算法伪代码
该研究团队在非凸优化理论框架下,得到如下关于收敛界的结论:
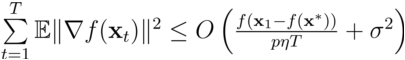
其中T表示迭代次数,p、η、σ均为参数,f表示损失函数。从上述结论可推论出RAda在非凸条件下可以收敛到一个具有δ精度的近似解。
RAda算法的一个重要优势是每轮迭代的计算成本很低,不仅耗时少,而且对硬件算力的要求也很低。为此,实验部分对RAda算法的计算成本进行了对比验证。图2展示了RAda和其他对比算法在CIFAR-10和CIFAR-100数据集上训练损失随运行时间的变化情况。RAda达到最好精度的运行时间最少,说明其计算成本最低。
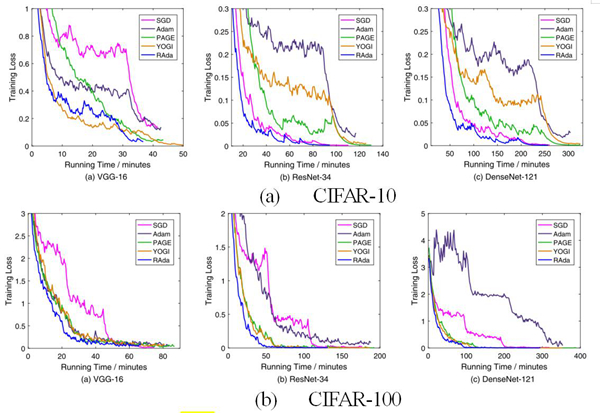 图2. 算法计算成本对比试验
图2. 算法计算成本对比试验
综上,该研究工作从理论上证明了RAda在非凸情况下具有理论保证的收敛性,并且通过实验验证了该算法的计算成本比其他主流算法更低,这可以帮助完成很多场景下的深度模型训练任务,尤其是在边缘计算中端侧算力严重受限的情况下。因此,在边缘端人工智能芯片研发领域具有很大的应用前景。
相关工作以Randomized block-coordinate adaptive algorithms for nonconvex optimization problems为题发表在人工智能顶级期刊Engineering Applications of Artificial Intelligence上。文章第一作者为中国科学院苏州纳米技术与纳米仿生研究所博士研究生周扬帆,通讯作者为刘欣研究员。该工作得到了苏州市外国专家计划等项目的资助。
附件下载:

